


I. Introduction
Artificial Intelligence (AI) refers to the development of computer systems that can perform tasks typically requiring human intelligence. These tasks may include problem-solving, speech and image recognition, language understanding, and decision-making. AI systems use algorithms, models, and large amounts of data to learn and improve their performance over time. We have seen how to create an AI system, but How does AI learn?
Importance of AI in modern society
AI has become an integral part of modern society, revolutionizing various industries and changing how we live and work. From healthcare to finance, transportation to entertainment (including Deepfake technology), also can help in bridging society gap, AI has had a profound impact on how we process information and make decisions. By automating complex tasks and providing insights through data analysis, AI can improve efficiency, accuracy, and productivity across a wide range of applications.
How does AI Learn: Overview
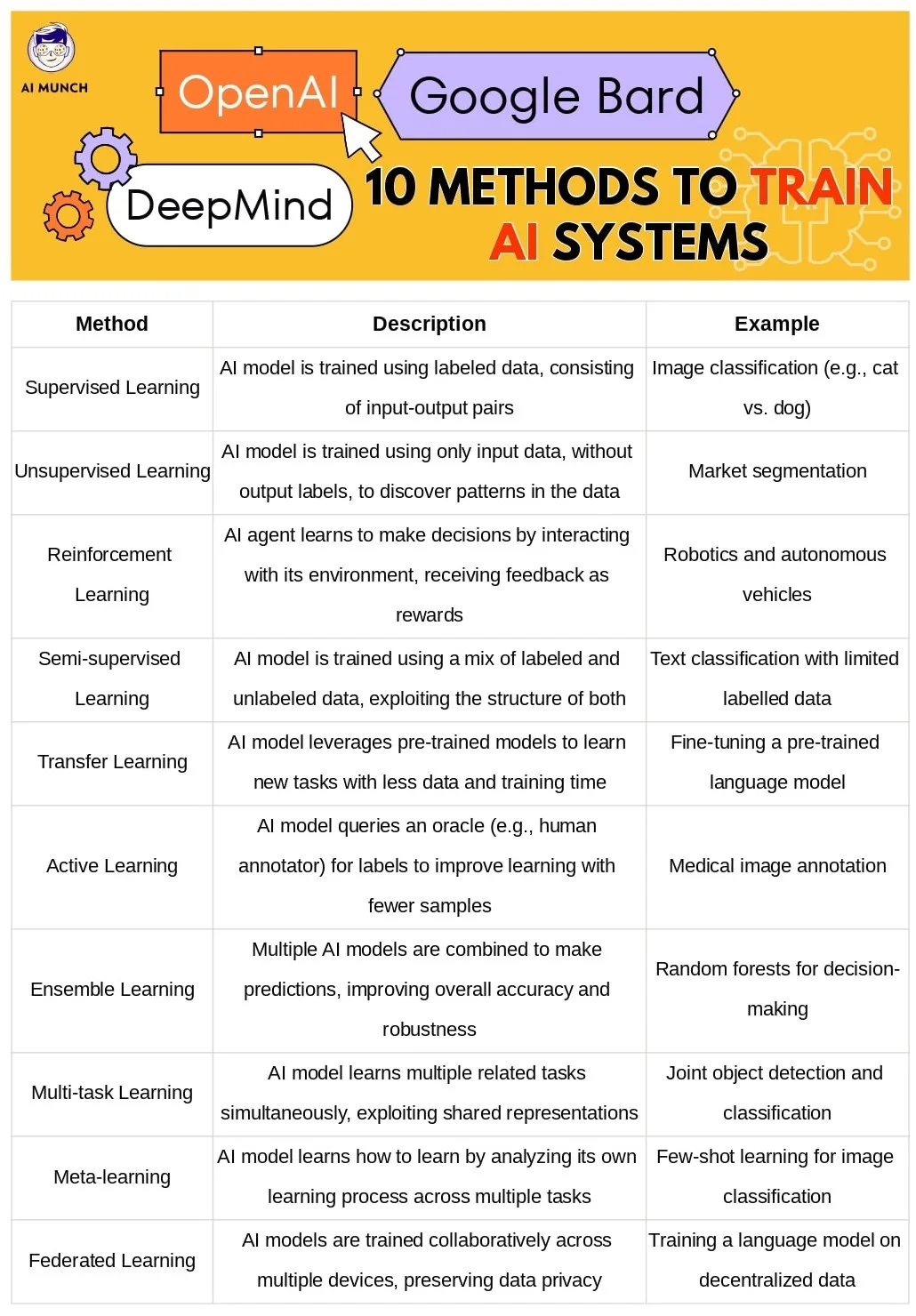
AI systems learn through various methods, which involve processing and interpreting vast amounts of data to recognize patterns, make predictions, and ultimately, make decisions. The learning process generally consists of data collection, model training, and model deployment. AI systems can be trained using different learning approaches, such as supervised learning, unsupervised learning, and reinforcement learning.
II. Types of AI Learning
A. How does AI Learn: Supervised Learning
1. Definition and explanation
Supervised learning is a type of AI learning where the model is trained using labelled data, which includes both input and corresponding output data. The model learns to make predictions by finding the relationship between input and output data. This learning process involves minimizing errors through iterative adjustments of the model’s parameters.
2. Example: Image recognition
A common application of supervised learning is image recognition, where an AI model is trained to classify images into different categories. For example, a model can be trained to identify whether an image contains a cat or a dog by providing it with numerous labelled images of cats and dogs. The model learns to recognize the features that distinguish cats from dogs and can then classify new, unlabeled images accordingly.
B. How does AI Learn: Unsupervised Learning
1. Definition and explanation
Unsupervised learning is a type of AI learning in which the model is trained using only input data without any corresponding output labels. Unsupervised learning aims to find patterns, relationships, or structures within the data. This is typically achieved through clustering or dimensionality reduction techniques.
2. Example: Market segmentation
An example of unsupervised learning is market segmentation, where businesses analyze customer data to identify distinct groups with similar characteristics. By using clustering algorithms, an AI model can analyze various factors, such as demographics, purchasing behaviour, and preferences, to group customers into different segments. This information can then be used to tailor marketing strategies and better target specific customer groups.
C. How does AI Learn: Reinforcement Learning
1. Definition and explanation
Reinforcement learning is a type of AI learning in which an agent learns to make decisions by interacting with its environment. The agent receives feedback in the form of rewards or penalties for its actions, allowing it to adjust its behaviour and improve its decision-making process over time. The goal is to maximize the cumulative reward by discovering the optimal sequence of actions.
2. Example: Robotics and autonomous vehicles
One application of reinforcement learning is in the field of robotics and autonomous vehicles. For example, a self-driving car can use reinforcement learning to navigate through traffic, make lane changes, and avoid obstacles. The AI agent receives positive rewards for reaching its destination and negative rewards for collisions or traffic violations. The self-driving car learns to make better decisions and improve its overall performance by continuously interacting with its environment.
III. How does AI Learn: Frameworks and Algorithms
A. Neural Networks
1. Overview and structure
This is the most important term when we talk about ‘How does AI Learn’. Neural networks are a type of AI learning framework inspired by the structure and function of the human brain. They consist of interconnected layers of nodes, called neurons, which process and transmit information. Neural networks typically include an input layer, one or more hidden layers, and an output layer. Each neuron receives input from multiple neurons in the previous layer, processes the information, and passes the result to the neurons in the next layer. The strength of the connections between neurons is adjusted during the learning process, allowing the network to adapt and improve its performance.
2. Examples: Deep learning and convolutional neural networks
Deep learning is a subset of neural networks that employs deep architectures with many hidden layers. These deep networks can model complex patterns and representations in data, making them particularly suited for tasks such as image and speech recognition, natural language processing, and game playing.
Convolutional neural networks (CNNs) are a specialized type of neural network designed for processing grid-like data, such as images. CNNs use convolutional layers to scan the input data for local patterns, such as edges, textures, or shapes, and then use pooling layers to reduce the spatial dimensions. CNNs have been successful in various computer vision tasks, including image classification, object detection, and segmentation.
B. Decision Trees
1. Overview and structure
Decision trees are an AI learning framework that can be used for classification and regression tasks. They represent a series of decisions or tests organized in a hierarchical structure resembling a tree. Each internal node in the tree represents a decision based on a particular feature of the input data, and each leaf node represents a predicted output or class. The learning process involves recursively splitting the data based on the feature that provides the best separation of the target variable.
2. Examples: Classification and regression tasks
Decision trees can be applied to a wide range of tasks, such as diagnosing medical conditions based on patient symptoms, predicting customer churn for a business, or estimating house prices based on property features. They are particularly useful for tasks that require interpretable and explainable models, as the decision process can be easily visualized and understood.
C. Support Vector Machines
1. Overview and structure
Support vector machines (SVMs) are a type of AI learning framework used for classification and regression tasks. SVMs aim to find the optimal decision boundary, called the hyperplane, that maximizes the margin between different classes in the input space. The margin is defined as the distance between the hyperplane and the closest data points, called support vectors. SVMs can handle linearly separable data as well as nonlinearly separable data by transforming the input space into a higher-dimensional space using kernel functions.
2. Examples: Text and image classification
SVMs have been successfully applied to various classification tasks, such as text classification for sentiment analysis or spam detection and image classification for object recognition or face detection. Their ability to handle high-dimensional data and their robustness to outliers make them well-suited for these tasks.
D. Clustering Algorithms
1. Overview and structure
Clustering algorithms are a type of unsupervised AI learning framework that aims to group data points based on their similarity or proximity. The goal is to identify clusters or groups within the data where points within the same cluster are more similar to each other than points in different clusters. Clustering algorithms can be divided into several categories, such as partition-based, hierarchical, or density-based, depending on the approach used to form the clusters.
2. Examples: K-means and hierarchical clustering
K-means and hierarchical clustering are two popular unsupervised learning algorithms used for clustering, which is the process of grouping similar data points together based on their features.
a. K-means clustering:
K-means is a partition-based clustering algorithm that aims to divide the data into K distinct clusters, where each data point belongs to the cluster with the nearest mean (centroid). The main steps in the K-means algorithm are:
- Initialize K centroids randomly.
- Assign each data point to the nearest centroid.
- Update the centroids by calculating the mean of all the data points within each cluster.
- Repeat steps 2 and 3 until the centroids’ positions do not change significantly or a predetermined stopping criterion is met.
K-means is often used for its simplicity and efficiency, making it suitable for large datasets. However, it requires the user to specify the number of clusters (K) beforehand, and its performance can be sensitive to the initial placement of centroids.
Example: K-means clustering can be used to segment customers based on their purchasing behaviour, allowing companies to target their marketing efforts more effectively.
b. Hierarchical clustering:
Hierarchical clustering is an agglomerative clustering algorithm that builds a tree-like structure (dendrogram) to represent the hierarchical relationships between data points. The main steps in hierarchical clustering are:
- Treat each data point as a single cluster.
- Find the two clusters with the smallest distance between them and merge them into a new cluster.
- Update the distance matrix to reflect the new cluster.
- Repeat steps 2 and 3 until only one cluster contains all data points.
Hierarchical clustering does not require the user to specify the number of clusters beforehand, and the dendrogram can be cut at different levels to obtain different clustering configurations. However, hierarchical clustering can be computationally expensive for large datasets, and the choice of distance metric and linkage method can impact the clustering results.
Example: Hierarchical clustering can be used to group similar articles or documents based on their content, facilitating content organization and recommendation in news websites or content platforms.
IV. AI Learning Process
A. Data Collection
- Importance of quality data
Quality data is essential for training accurate and reliable AI models. The data used for training should be representative of the real-world scenarios the model will encounter, diverse to capture various edge cases, and large enough to allow the model to generalize effectively. Poor-quality data can lead to biased, overfitted, or underperforming models, which may not provide reliable predictions or insights.
- Data preprocessing and cleaning
Before training an AI model, the collected data must be preprocessed and cleaned to ensure its quality and compatibility with the learning algorithms. This process may involve handling missing or inconsistent values, removing duplicates, and transforming or encoding features into suitable formats. Preprocessing can also include feature scaling, normalization, or dimensionality reduction to improve the efficiency and performance of the learning algorithms.
B. Model Training
- Splitting data into training and testing sets
To train and evaluate an AI model effectively, the collected data is typically split into two separate sets: a training set and a testing set. The training set is used to train the model, allowing it to learn the underlying patterns and relationships in the data. The testing set is used to evaluate the model’s performance, providing an unbiased estimate of its generalization capability to new, unseen data.
- Iterative learning and optimization
AI models learn through an iterative process, where the model’s parameters are updated based on its performance on the training data. This process can involve optimization techniques, such as gradient descent, which minimize the error or loss function that quantifies the discrepancy between the model’s predictions and the actual target values. The learning process continues until the model converges to an optimal set of parameters or a predefined stopping criterion is met.
- Evaluating model performance
Evaluating the performance of an AI model is crucial to ensure its accuracy and reliability. This typically involves using performance metrics, such as accuracy, precision, recall, or F1-score for classification tasks, and mean squared error, mean absolute error, or R-squared for regression tasks. These metrics allow for the comparison of different models and help determine the best model for the given task.
C. Model Deployment
- Integration into existing systems
Once an AI model has been trained and its performance is deemed satisfactory, it can be deployed into existing systems to provide predictions or insights. This process may involve integrating the model into software applications, APIs, or cloud-based services. It is essential to ensure that the model can handle real-world data and scale to accommodate the desired workload during deployment.
- Continuous improvement and updates
AI models should be continuously monitored and updated to maintain their performance and relevance over time. This can involve retraining the model with new data, adjusting its parameters, or updating the learning algorithms. Continuous improvement also includes monitoring the model’s performance in production, addressing any issues that arise, and incorporating feedback from users to enhance the model’s overall effectiveness.
V. Ethical Considerations
A. Bias in AI systems
- Sources and consequences
Ethical Considerations are very important when we talk about ‘How does AI learn’. Bias in AI systems can arise from various sources, including biased training data, biased algorithms, or even biased human judgments during data labelling. Biased AI models can lead to unfair or discriminatory outcomes, perpetuating existing social inequalities and stereotypes. Consequences of bias in AI systems can range from poor user experience to more severe issues, such as wrongful denial of loans, biased hiring practices, or unfair treatment in healthcare.
- Strategies for mitigating bias
Bias is one of the dark sides of AI. To mitigate bias in AI systems, it is essential to address it at various stages of the AI learning process. This can include using diverse and representative training data, employing unbiased data labeling practices, and applying fairness-aware machine learning algorithms. Additionally, conducting thorough bias audits and involving diverse stakeholders in the development process can help ensure more fair and equitable AI systems.
B. Data Privacy
- Importance of protecting user data
Protecting user data is crucial to ensure the ethical use of AI systems. Unauthorized access, misuse, or sharing of sensitive user data can lead to privacy violations, identity theft, or other malicious activities. Ensuring data privacy not only helps build user trust in AI systems but also complies with legal and regulatory requirements in many jurisdictions.
- Regulations and best practices
Several data protection regulations, such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States, govern user data collection, processing, and storage. Best practices for data privacy in AI systems include anonymizing and encrypting data, implementing strict access controls, and conducting regular privacy audits. Furthermore, embracing privacy-by-design principles, where privacy considerations are integrated into the development process, can help create more privacy-respecting AI systems.
VI. Conclusion
A. Recap of How does AI Learn and examples
This article explored various aspects of AI learning, including supervised, unsupervised, and reinforcement learning, along with examples of their applications. We also discussed different AI learning frameworks and algorithms, such as neural networks, decision trees, support vector machines, and clustering algorithms. The AI learning process, consisting of data collection, model training, and deployment, was described, highlighting the importance of quality data and performance evaluation.
B. Future developments and challenges in AI learning
As AI technology continues to advance, new learning techniques and algorithms will likely emerge, enabling AI systems to tackle more complex and diverse tasks. Challenges, such as addressing bias, ensuring data privacy, and improving AI models’ interpretability, will remain critical areas of focus to ensure ethical and responsible AI development.
C. The potential impact of AI on various industries and society
The advancements in AI learning have the potential to transform various industries, leading to increased efficiency, productivity, and innovation. From healthcare and finance to transportation and entertainment, AI will continue to reshape how we live and work. Embracing responsible AI development and addressing ethical concerns will help maximize the benefits of AI while minimizing potential risks and negative consequences.
FAQs about How does AI Learn
AI learns from examples by analyzing and identifying patterns in the data provided. In supervised learning, AI models use labeled data, which consist of input-output pairs, to learn the relationship between inputs and outputs. The model iteratively adjusts its parameters based on its performance on the training data until it converges to an optimal set of parameters or a predefined stopping criterion is met. The AI model can generalize its learning to new, unseen data.
Artificial intelligence learns things through various learning methods, including supervised learning, unsupervised learning, and reinforcement learning. These methods help AI models identify patterns, relationships, and structures in the data, allowing them to make predictions or decisions based on their learning. The learning process typically involves iterative optimization techniques, such as gradient descent, to minimize the discrepancy between the model’s predictions and the actual target values.
A learning-based AI model is a model that learns from data to make predictions or decisions. One example is a spam email classifier. Using supervised learning, the AI model is trained on a dataset containing emails labeled as either “spam” or “not spam.” The model learns to identify patterns and features that distinguish spam emails from non-spam emails. Once trained, the AI model can classify new, unseen emails as spam or not spam based on the patterns it learned during training.
The three main types of learning in AI are:
a. Supervised Learning: AI models learn from labeled data consisting of input-output pairs, enabling them to predict outputs for new inputs. Example: Image classification.
b. Unsupervised Learning: AI models learn from input data without output labels, identifying patterns and structures within the data. Example: Clustering algorithms for market segmentation.
c. Reinforcement Learning: AI agents learn by interacting with their environment, receiving feedback in the form of rewards or penalties, and adjusting their actions to maximize cumulative rewards. Example: Robotics and autonomous vehicles.
a. Virtual Assistants: AI-powered assistants, like Siri or Alexa, use natural language processing and machine learning to understand user queries and provide relevant information or perform tasks.
b. Image Recognition: AI systems, such as convolutional neural networks, can recognize objects, faces, or scenes in images, enabling applications like object detection, facial recognition, and medical image analysis.
c. Machine Translation: AI models, like those based on transformer architectures, can automatically translate text between languages with high accuracy, enabling real-time translation services and improving cross-language communication.
Do you want to read more? Check out these articles.






1 comment