


Table of Contents Show
I. Introduction
Machine learning (ML) is a subfield of artificial intelligence (AI) that enables computer systems to learn and improve from experience without being explicitly programmed automatically. It is an application of statistical methods to large datasets and has the potential to help solve complex problems across various fields, including healthcare, finance, and business. In recent years, machine learning has become increasingly important as the amount of data being generated has exploded and the computing power required to process this data has become more affordable.
This article is intended for beginners who are interested in learning about ML but have little to no background in the field. We will start with the basics and gradually develop to more advanced topics. Even if you have no programming experience, this article will provide a solid foundation for you to understand the key concepts and get started with machine learning.
II. Understanding the Basics of Machine Learning
A. Definition of key terms:
Before diving into the details of machine learning, it’s important to define some key terms. Supervised learning is a type of machine learning in which the algorithm is trained on a labelled dataset, meaning that the input data has a corresponding output or “label”. On the other hand, unsupervised learning is used when the dataset is unlabeled and the algorithm must find patterns or structures on its own. Reinforcement learning is a machine learning type involving an agent interacting with an environment to learn how to make decisions that maximize a reward.
B. Explanation of the difference between supervised and unsupervised learning:
In supervised learning, the algorithm is provided with a labelled dataset and learns to make predictions based on that data. For example, if we want to build a model that can predict whether an email is spam or not, we would train it on a dataset of labelled emails (spam or not spam) and then use it to classify new, unseen emails. In unsupervised learning, the algorithm is given an unlabeled dataset and must find patterns or structures on its own. For example, if we want to group similar customers based on their purchase history, we might use unsupervised learning to cluster customers based on their buying patterns.
C. Discussion of the steps involved in a typical machine learning project:
A typical machine learning project involves several steps. First, we need to collect and preprocess the data, which may involve cleaning the data, handling missing values, and selecting relevant features. Once the data is ready, we can start training our model, which involves selecting an appropriate algorithm and tuning its hyperparameters to achieve the best performance. After training the model, we evaluate its performance on a test set and fine-tune it as necessary. Finally, we deploy the model to make predictions on new, unseen data. Throughout the process, we must keep in mind issues such as overfitting, bias, and fairness to ensure that our model is accurate and unbiased.
III. Types of Machine Learning Algorithms
A. Overview of popular machine learning algorithms:
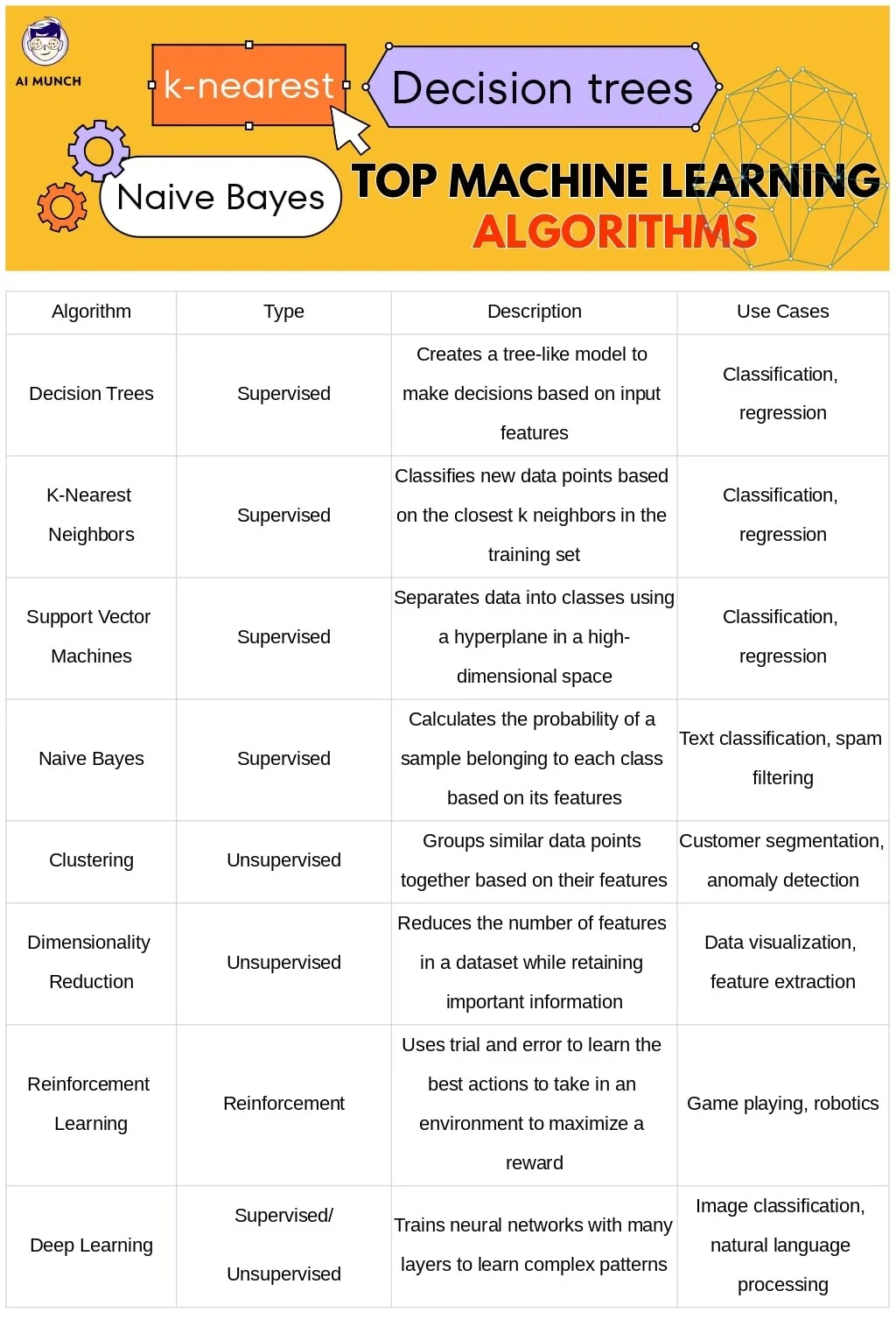
There are many machine learning algorithms, each with its own strengths and weaknesses. Some popular algorithms include Decision trees, k-nearest neighbours, support vector machines (SVMs), and Naive Bayes. Decision trees are supervised learning algorithms that make predictions based on a series of if-then-else conditions. K-nearest neighbours is another type of supervised learning algorithm that finds the k-closest data points to a new sample and uses their labels to make a prediction. SVMs are powerful algorithms that can separate data into classes using a hyperplane in a high-dimensional space. Naive Bayes is a probabilistic algorithm that is commonly used for text classification tasks.
B. Explanation of how these algorithms work and what types of problems they are best suited for:
Each algorithm has its own strengths and weaknesses and is best suited for certain types of problems. Decision trees, for example, are easy to interpret and can handle both categorical and numerical data, making them a good choice for classification tasks. K-nearest neighbours is good for classification tasks when there are relatively few features but they can be slow on large datasets. SVMs are powerful algorithms that can handle complex datasets and are good for binary classification tasks. Naive Bayes is fast, efficient, and commonly used for text classification tasks.
C. Discussion of deep learning algorithms and neural networks:
Deep learning is a subset of Machine Learning that involves training neural networks with many layers. Neural networks are a type of algorithm that is modelled after the structure of the brain, with interconnected nodes that process and transmit information. Deep learning has revolutionized fields such as computer vision and natural language processing, enabling machines to perform highly accurate tasks such as image recognition and language translation.
IV. Data Preprocessing and Feature Engineering
A. Explanation of why data preprocessing is necessary:
Data preprocessing is necessary to ensure that the data is in a format that can be used by machine learning algorithms. Data may need to be cleaned, normalized, or transformed to ensure the model can learn from it effectively. For example, missing values may need to be imputed, and categorical data may need to be encoded as numerical values.
B. Overview of common techniques for data preprocessing:
There are many techniques for data preprocessing, including normalization, feature scaling, and handling missing data. Normalization is a technique that scales the data so that each feature has a similar range. Feature scaling is a technique that ensures that each feature has a similar variance. Handling missing data involves imputing missing values or removing them from the dataset.
C. Discussion of feature engineering and how it can improve model performance:
Feature engineering is the process of selecting and creating features that are relevant to the problem at hand. This can involve transforming or combining existing features or creating new features from scratch. Feature engineering can improve model performance by reducing the dimensionality of the dataset, making it easier for the model to learn from the data, and by ensuring that the model focuses on the most important features. However, it can also be time-consuming and require domain knowledge.
V. Model Training and Evaluation
A. Explanation of the different methods for model training:
There are different methods for training machine learning models, including batch learning and online learning. Batch learning involves training the model on the entire dataset at once, while online learning involves training the model on smaller batches of data over time. Online learning can be useful for tasks requiring real-time updates and can handle constantly changing data.
B. Discussion of cross-validation and how it can be used to evaluate model performance:
Cross-validation is a technique used to evaluate a model’s performance on a dataset. It involves splitting the data into multiple folds, training the model on each fold, and evaluating its performance on the remaining folds. This helps to ensure that the model is not overfitting to the training data and can generalize well to new data.
C. Overview of popular evaluation metrics:
There are many evaluation metrics that can be used to measure a model’s performance, including accuracy, precision, recall, and F1 score. Accuracy measures the percentage of correct predictions, while precision measures the percentage of correct positive predictions, and recall measures the percentage of actual positives that were correctly predicted. The F1 score is a harmonic mean of precision and recall and a useful metric for dealing with imbalanced datasets.
VI. Machine Learning Tools and Libraries
A. Overview of popular machine learning tools and libraries:
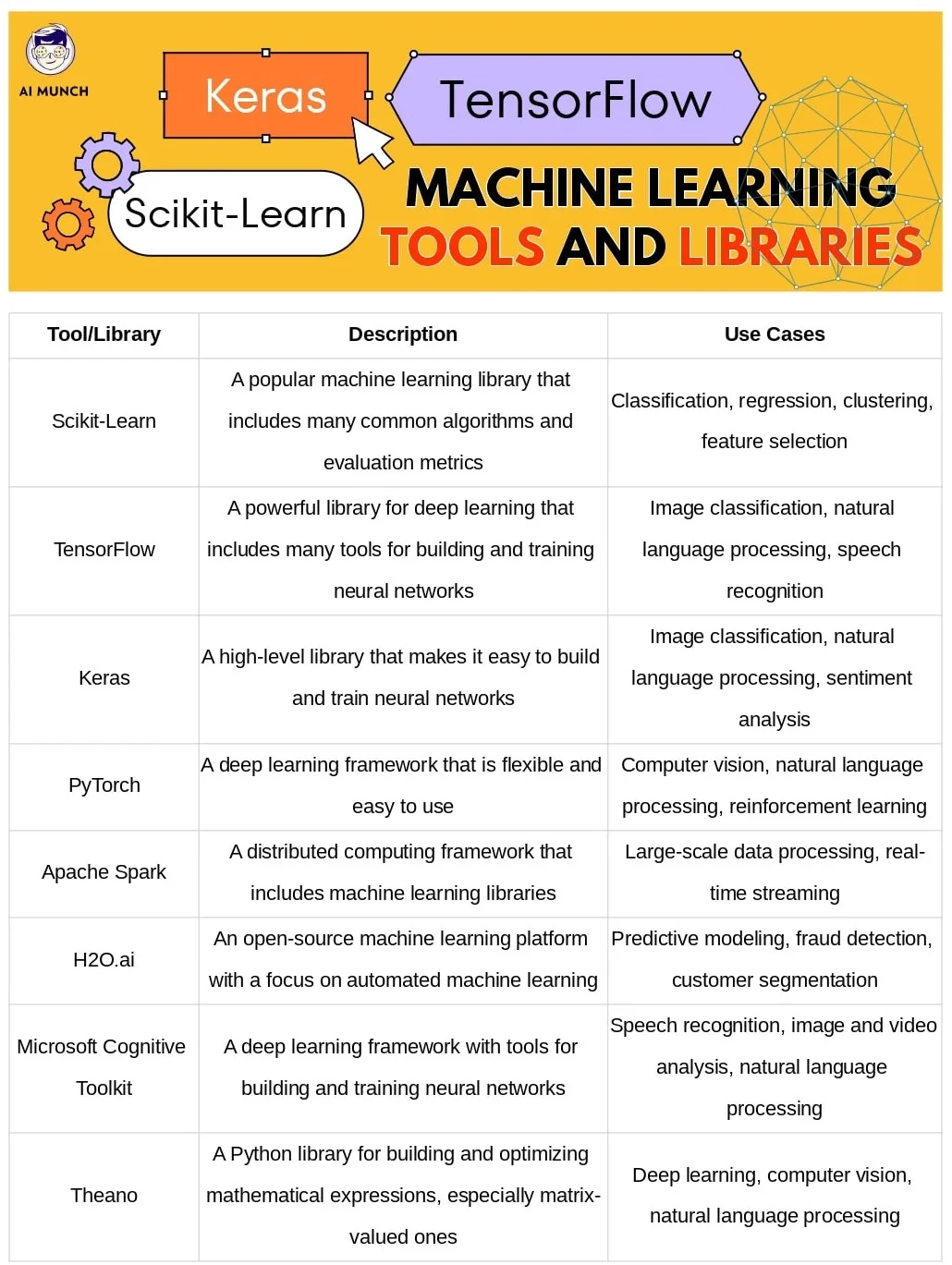
Many machine-learning tools and libraries are available, including Scikit-Learn, TensorFlow, and Keras. Scikit-Learn is a popular machine-learning library that includes many common algorithms and evaluation metrics. TensorFlow is a powerful library for deep learning and is widely used for tasks such as image classification and natural language processing. Keras is a high-level library that makes building and training neural networks easy.
B. Explanation of how to install and use these tools:
Installing and using these tools can vary depending on the specific library and your programming environment. Many libraries can be installed using a package manager such as pip or conda. Once installed, you can import the library into your code and start using its functions and classes.
VII. Tips for Success in Machine Learning
A. Discussion of best practices for data collection, preprocessing, and modelling:
To succeed in machine learning, it’s important to follow best data collection, preprocessing, and modelling practices. This includes ensuring that the data is representative of the problem at hand, preprocessing the data to remove noise and ensure that it is in a format that can be used by machine learning algorithms, and selecting the appropriate model and hyperparameters to achieve the best performance.
B. Explanation of how to choose the right algorithm and evaluation metrics for a given problem:
Choosing the right algorithm and evaluation metrics is crucial for achieving good performance in machine learning. This involves understanding the strengths and weaknesses of different algorithms and selecting the one best suited for the specific problem. It also involves selecting appropriate evaluation metrics relevant to the problem and ensuring that the model performs well.
C. Tips for avoiding common pitfalls in machine learning:
ML has many common pitfalls, such as overfitting, underfitting, and bias. To avoid these pitfalls, it’s important to follow best practices for data collection, preprocessing, and modelling and use techniques such as regularization and cross-validation. It’s also important to be aware of potential biases in the data and to ensure that the model is fair and unbiased.
VIII. Conclusion
In this article, we have provided a comprehensive guide to machine learning for beginners. We have explained the basics of ML, including key terms and the steps involved in a typical ML project. We have also discussed different types of ML algorithms, the importance of data preprocessing and feature engineering, and how to train and evaluate ML models. Finally, we have provided tips for success in machine learning and avoiding common pitfalls.
Encouragement for readers to continue learning about machine learning and its applications:
Machine learning is a rapidly growing field with many exciting applications across various industries. We encourage readers to continue learning about ML and its applications and to experiment with different algorithms and techniques. There are many resources available for further learning, including online courses, books, and tutorials. With the right skills and knowledge, you can leverage the power of ML to solve complex problems and positively impact the world.
FAQs
The three C’s of machine learning are collaboration, computation, and customization. Collaboration involves working with others to gather data, build models, and evaluate results. Computation involves using powerful computing resources to train and run ML models. Customization involves tailoring ML models to specific use cases and domains.
AI is a broad field that encompasses many different technologies and approaches for creating intelligent machines. Machine learning is a subset of AI that involves training machines to learn from data and make predictions or decisions without being explicitly programmed. In other words, ML is a specific technique used to achieve AI.
The three types of machine learning are supervised, unsupervised, and reinforcement. Supervised learning involves training a model using labeled data to make predictions or decisions. Unsupervised learning involves training a model on unlabeled data to identify patterns or relationships in the data. Reinforcement learning involves training a model to make decisions based on feedback from its environment.
The four basics of machine learning are data collection, data preprocessing, model training, and model evaluation. Data collection involves gathering relevant data to train the machine learning model. Data preprocessing involves cleaning and preparing the data for analysis. Model training involves building and optimizing the ML model using the prepared data. Model evaluation involves assessing the performance of the model on a separate test dataset.
Machine learning can be used in many different applications, including image recognition, natural language processing, fraud detection, and predictive maintenance. For example, machine learning algorithms can be trained to recognize objects in images, such as faces or buildings, or to classify text as positive or negative sentiment.
Machine learning is a subset of artificial intelligence (AI) that involves teaching machines to learn from data and make predictions or decisions without being explicitly programmed. It uses statistical algorithms and models to identify patterns in data and make predictions or decisions based on those patterns.
Do you want to read more? Check out these articles.





2 comments